
Video compression is something of a black box for many people. If you ask most folks, they’ll probably tell you that videos are compressed using math on the ones and zeroes of the video file. And while that glib answer is basically correct, it’s much more interesting than that. Let’s check out how video compression works, without getting out the uncommon Greek characters.
Of course, computers are basically math machines, so definable mathematical formulas are at the core of nearly every computer operation, especially around video and photo processing. What we’re about to discuss doesn’t require a deep foundation in math, but some comfort with the ideas of data compression and encoding will aid in your understanding.
What Is Video Compression?
Video compression algorithms look for spatial and temporal redundancies. By encoding redundant data a minimum number of times, file size can be reduced. Imagine, for example, a one-minute shot of a character’s face slowly changing expression. It doesn’t make sense to encode the background image for every frame: instead, you can encode it once, then refer back to it until you know the video changes.
This interframe prediction encoding is what’s responsible for one of digital video compression’s unnerving artifacts: parts of an old image moving with incorrect motion like an improperly animated dummy, until a new I-frame comes and wipes it all away.
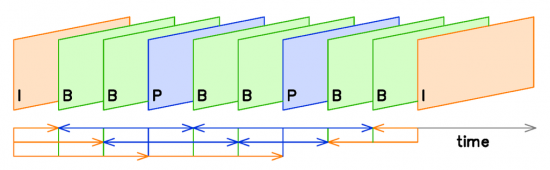
How Video Compression Works: I-frames, P-frames, and B-frames

I-frames are fully encoded images. Every I-frame contains all the data it needs to represent an image, which specific values stored for every pixel, just like a JPEG. P-frames are predicted based on how the image changes from the last I-frame. B-frames are bi-directionally predicted, using data from both the last P-frame and the next I-frame. To save size, P-frames store only the changes between frames, called deltas, which are encoded in mathematical form as motion vectors. In the above example, the P-frame needs to track how the dots move across the frame, but Pac-Man doesn’t need to be stored redundantly.
The B-frame looks at the P-frame and the next I-frame and “averages” the change across those frames. The algorithm has an idea of where the image “starts” (the first I-frame) and where the image “ends” (the second I-frame), and it uses partial data to encode a good guess, leaving out all the redundant static pixels that aren’t necessary to create the image.
Intraframe Encoding (I-frames)
I-frames are compressed independently, in the same way still images are saved. Because I-frames use no predictive data, the compressed image contains all the data used to display the I-frame. They are still compressed by an image compression algorithm like JPEG. This encoding often takes places in the YCbCr color space, which separates luminosity data from color data, allowing motion and color changes to be encoded separately.
Most codecs, including H.264, use predictive frames (P- and B-frames) between fully-stored I-frames. I-frames are periodically shown to “refresh” the data stream by setting a new reference frame. The farther apart the I-frames, the smaller the video file can be. However, if I-frames are too far apart, the accuracy of the video’s predictive frames will slowly degrade into unintelligibility.
A bandwidth-optimized application would insert I-frames as infrequently as possible without breaking the video stream. For consumers, the frequency of I-frames is often determined indirectly by a quality slider. Professional-grade video compression software like ffmpeg allows frame-specific control over I-frame creation and frequency.
Interframe Prediction (P-frames and B-frames)
Video encoders attempt to “predict” change from one frame to the next. The closer its predictions, the more effective the compression algorithm. The quality and precision of the prediction varies from codec to codec, which each employing subtly different mathematical methods to accomplish the same goal. The exact amount, frequency, and order of predictive frames, as well as the specific algorithm used to encode and reproduce them, is determined by the specific algorithm you use.
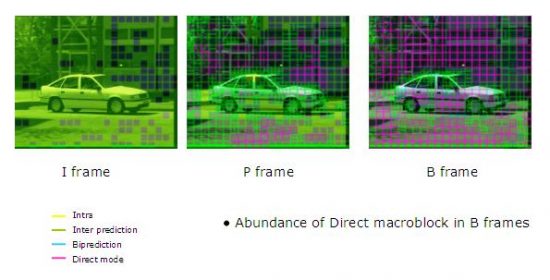
Frame prediction works on the “block” scale, which are individual sections of a frame that can be analyzed linearly over time. The frame is divided into identically-sized sections called macroblocks, typically consisting of 16 x 16 samples.
The algorithm does not encode the raw pixel values for each block. Instead, the encoder captures the change from frame to frame within an individual block, called a delta. When the video is played back, the video player will interpret the deltas stored as motion vectors to “retranslate” the video.
If the block doesn’t change, no vector is needed. The frame is effectively “transparent” at those blocks. The I-frames blocks will continue to be shown as the other parts of the P-frame change.
P- and B-frames store the deltas only, save the changes between reference frames but not the full information about the image. The value of the P-frame’s blocks is calculated from values in the I-frames’ blocks. Those values provide a “home base” for image prediction, letting the algorithm use instructions like “10-percent darker” to compress data.
How Video Compression Works: Data Compression
Once the data is sorted into its frames, then it’s encoded into a mathematical expression with the transform encoder. H.264 employs a DCT (discrete-cosine transform) to change visual data into mathematical expression (specifically, the sum of cosine functions oscillating at various frequencies.) The chosen compression algorithm determines the transform encoder.
Then the data is “rounded” by the quantizer. Finally, the bits are run through a lossless compression algorithm to shrink the file size one more time. This doesn’t change the data: it just organizes it in the most compact form possible. Then, the video is compressed, smaller than before and ready for watching.
You might also be interested in the following posts:


